

As a member of DIR Core Facilities, the Bioinformatics and Computational Biology (BCB) Core facilitates, amplifies, and accelerates biological and medical research and discovery through the application of the latest bioinformatics methods and technologies. This mission is achieved by delivering high quality and comprehensive support for experimental design, analysis and visualization in a timely fashion. The core is responsive to research scientists’ needs and effectively evolve with advances in the field.
Integrative Multi-Omics Analysis Section
|
- Omics Analysis
- Genomics (Genome, exome and targeted DNA-seq),
- Transcriptomics (Microarray and RNA-seq),
- Epigenomics (Methyl-seq, ChIP-seq, etc.),
- Proteomics, and Metabolomics
- Gene/Target/Disease Analysis: Functional annotation at variant, gene, and gene set level, Interaction analysis, and Pathway enrichment analysis
- Ad-hoc consultation: Advice on experimental designs, data management, and analysis
- Computing resource development and maintenance, including Bioinformatics Software Development: Systems Toolkits Development, customized biological databases, and Web Services development
- Training: Personalized training to match user’s specific requirements and group training and workshops
- Highlighted projects:
- Misregulation of ELK1, AP1, and E12 Transcription Factor Networks Is Associated with Melanoma Progression. [Singh, et. al. Cancers. 2020]
- Whole genome sequence-based haplotypes reveal a single origin of the 1393 bp HBB deletion. [Wang, et. al. J Med Genet. 2020]
- In vivo functional analysis of non-conserved human lncRNAs associated with cardiometabolic traits. [Ruan, et. al. Nat Commun. 2020]
- Affected Sib-Pair Analyses Identify Signaling Networks Associated With Social Behavioral Deficits in Autism. [Pirooznia, et. al. Front Genet. 2019]
- De novo variation in bipolar disorder. [Goes, et. al. Mol Psychiatry. 2019]
- IKAP-Identifying K mAjor cell Population groups in single-cell RNA- sequencing analysis. [Chen, et. al. Gigascience. 2019]
- Circulating Lymphangioleiomyomatosis Tumor Cells With Loss of Heterozygosity in the TSC2 Gene Show Increased Aldehyde Dehydrogenase Activity. [Pacheco-Rodríguez, et. al. Chest. 2019]
- Neutrophil Subsets, Platelets, and Vascular Disease in Psoriasis. [Teague, et. al. JACC Basic Transl Sci. 2019]
- Ancient Ancestry Informative Markers for Identifying Fine-Scale Ancient Population Structure in Eurasians. [Esposito, et. al. Genes (Basel). 2018]
- The transcription factors TFE3 and TFEB amplify p53 dependent transcriptional programs in response to DNA damage. [Brady, et. al. Elife. 2018]
- Human retinoic acid-regulated CD161+ regulatory T cells support wound repair in intestinal mucosa. [Povoleri, et. al. Nat Immunol. 2018]
- Targeted RNA-sequencing for the quantification of measurable residual disease in acute myeloid leukemia. [Dillon, et. al. Haematologica. 2019]
- Mutations in the pancreatic secretory enzymes CPA1 and CPB1 are associated with pancreatic cancer. [Tamura, et. al. Proc Natl Acad Sci U S A. 2018]
- The Diversity of REcent and Ancient huMan (DREAM): A New Microarray for Genetic Anthropology and Genealogy, Forensics, and Personalized Medicine. [Elhaik, et. al. Genome Biol Evol. 2017]
- Genome-wide Methyl-Seq analysis of blood-brain targets of glucocorticoid exposure. [Seifuddin, et. al. Epigenetics. 2017]
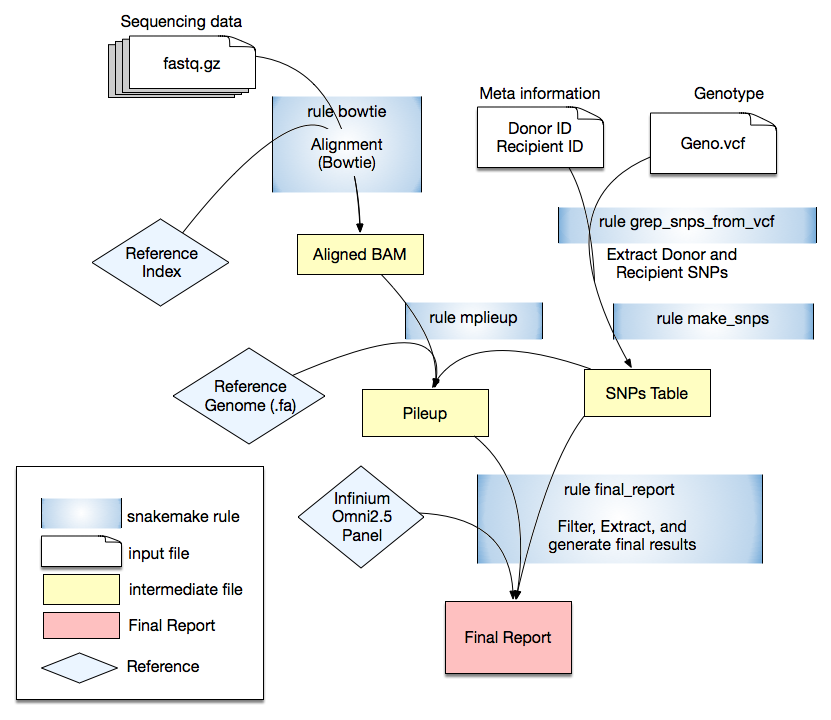
Cloud and On-Premise Automation Section
Section head: Dr. Ilker Tunc
|
- Highlighted projects:
- cfCloud: A Cloud-based Workflow for Cell-Free DNA Data Analysis. [Tunc, et al. 2020]
- Donor-derived cell-free DNA predicts allograft failure and mortality after lung transplantation. [Agbor, et. al. EBioMedicine. 2019]
- Circulating cell-free DNA as a biomarker of tissue injury: Assessment in a cardiac xenotransplantation model. [Agbor, et. al. J Heart Lung Transplant.]
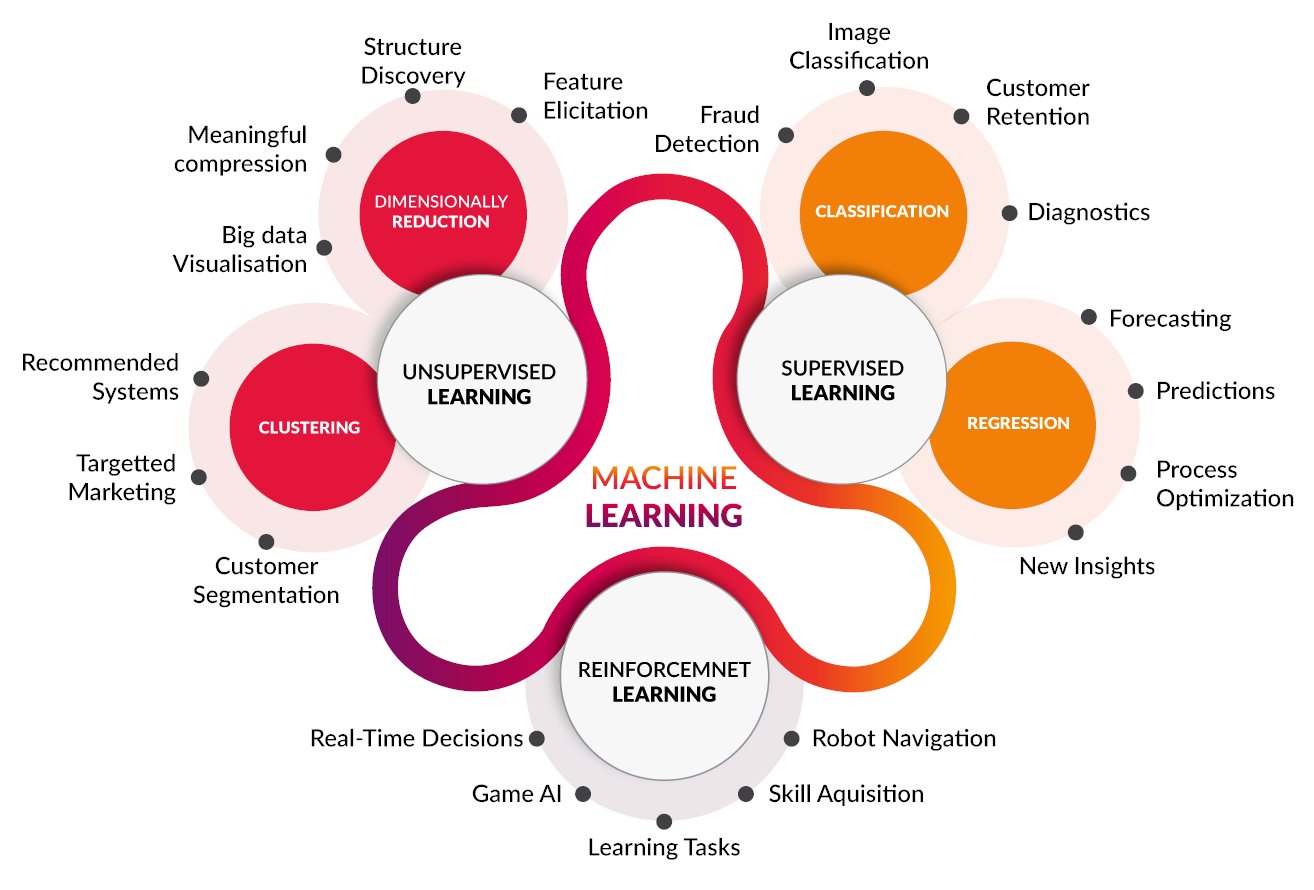
Statistical and Machine Learning Section
Section head: Dr. Yun-Ching Chen
Image source: cognub
|
- Highlighted projects:
- Develop a hybrid likelihood ratio model for prioritizing causal genes using genome sequencing data [Chen, et.al., PLoS Genet, 2013]
- Develop a probabilistic graphical model to predict human phenotypes using individual genome sequencing data [Cai, et.al., Hum Mutat, 2017 , Chen, et.al., PLoS Comput Biol, 2014 ]
- Association between DNA methylation and driver gene mutations and aberrant isoform expression in cancer [Chen, et.al., PLoS Comput Biol, 2017 , Chen, et.al., PLoS Comput Biol, 2019 ]
- Demonstrate connection of DNA methylation changes to the difference of ADHD symptom in monozygotic twins [Chen, et.al., Mol Psychiatry, 2017]
- Develop IKAP algorithm to facilitate identification of major cell populations in single-cell RNA-seq analysis [Chen, et.al., Gigascience, 2019]
- Test the ability of predicting cardiovascular risk from protein composition in lipoprotein [Gordon , et.al., Atherosclerosis, 2018]
- Examine correlation between cystic lung lesions and pulmonary function tests in LAM (lymphangioleiomyomatosis) patients